The Secret Life of Evaluators, with SAS
At the Western Users of SAS Software conference (yes, they DO know that is WUSS), I’ll be speaking about using SAS for evaluation.
“If the results bear any relationship at all to reality, it is indeed a fortunate coincidence.”
I first read that in a review of research on expectancy effects, but I think it is true of all types of research.
Here is the interesting thing about evaluation – you never know what kind of data you are going to get. For example, in my last post I had created a data set that was a summary of the answers players had given in an educational game, with a variable for the mean percentage correct and another variable for number of questions answered.
When I merged this with the user data set so I could test for relationships between characteristics of these individuals – age, grade, gender, achievement scores – and perseverance I found a very odd thing. A substantial minority were not matched in the users file. This made no sense because you have to login with your username and password to play the game.
The reason I think that results are often far from reality is just this sort of thing – people don’t scrutinize their data well enough to realize when something is wrong, so they just merrily go ahead analyzing data that has big problems.
In a sense, this step in the data analysis revealed a good problem for us. We actually had more users than we thought. Several months ago, we had updated our games. We had also switched servers for the games. Not every teacher installed the new software so it turned out that some of the records were being written to our old server.
Here is what I needed to do to fix this:
- Download the files from our servers. I exported these as .xls files.
- Read the files into SAS
- Fix the variables so that the format was identical for both files.
- Concatenate the files of the same type, e.g., student file the student file from the other server.
- Remove the duplicates
- Merge the files with different data, e.g., answers file with student file
I did this in a few easy steps using SAS.
- USE PROC IMPORT to read in the files.
Now, you can use the IMPORT DATA option from the file menu but that gets a bit tedious if you have a dozen files to import.
TIP: If you are not familiar with the IMPORT procedure, do it with the menus once and save the code. Then you can just change the data set names and copy and paste this a dozen times. You could also turn it into a macro if you are feeling ambitious, but let’s assume you are not. The code looks like this:
PROC IMPORT OUT= work.answers DATAFILE= “C:\Users\Spirit Lake\WUSS16\fish_data\answers.xls”
DBMS=EXCEL REPLACE;
RANGE=”answers$”;
GETNAMES=YES;
MIXED=NO;
SCANTEXT=YES;
USEDATE=YES;
SCANTIME=YES;
Assuming that your Excel file has the names of the columns – ( GETNAMES = YES) . All you need to do for the next 11 data sets is to change the values in lower case – the file name you want for your SAS file goes after the OUT = , the Excel file after DATAFILE = and the sheet in that file that has your data after the RANGE =.
Notice there is a $ at the end of that sheet name.
Done. That’s it. Copy and paste however many times you want and change those three values for output dataset name, location of the input data and the sheet name.
2. Fix the variables so that the format is identical for both files
A. How do you know if the variables are the same format for each file?
PROC CONTENTS DATA = answers ;
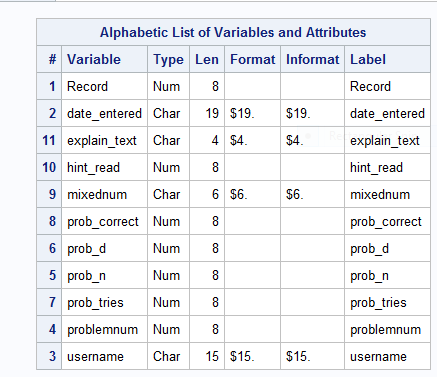
This LOOKS good, right?
B. Look at a few records from each file.
OPTIONS OBS= 3 ;
PROC PRINT DATA = fl_answers_new ;
VAR date_entered ;
PROC PRINT DATA = fl_answers_old ;
VAR date_entered ;
OPTIONS OBS = MAX ;
PAY ATTENTION HERE !!! The OPTIONS OBS = 3 only shows the first three records, that’s a good idea because you don’t need to print out all 7,000+ records . However, if you forget to change it back to OBS = MAX then all of your procedures after that will only use the first 3 records, which is probably not what you want.
So, although my PROC CONTENTS showed the files were the same format in terms of variable type and length, here was a weird thing, since the servers were in different time zones, the time was recorded as 5 hours different, so
2015-08-20 13:23:30
Became
2015-08-20 18:23:30
Since this was recorded as a character variable, not a date (see the output for the contents procedure above), I couldn’t just subtract 5 from the hour.
Because the value was not the same, if I sorted by username and date_entered , each one of these that was moved over from the old server would be included in the data set twice, because SAS would not recognize these were the same record.
So, what did I do?
I’m so glad you asked that question.
I read in the data to a new data set and the third statement gives a length of 19 to a new character variable.
Next, I create a variable that is the value of the date_entered variable that start at the 12th position and go for the next two (that is, the value of the hour).
Now, I add 5 to the hour value. Because I am adding a number to it , this will be created as a numeric value. Even though datefix1 is a character variable – since it was created using a character function, SUBSTR, when I add a number to it, SAS will try to make the resulting value a number.
Finally, I’m putting the value of datefixed to be the first 11 characters of the original date value , the part before the hour. I’m using the TRIM function to get rid of trailing blanks. I’m concatenating this value (that’s what the || does) with exactly one blank space. Next, I am concatenating this with the new hour value. First, though, I am left aligning that number and trimming any blanks. Finally, I’m concatenating the last 6 characters of the original date-time value. If I didn’t do this trimming and left alignment, I would end up with a whole bunch of extra spaces and it still wouldn’t match.
I still need to get this to be the value of the date_entered variable so it matches the date_entered value in the other data set.
I’m going to DROP the date_entered variable, and also the datefix1 and datefixn variables since I don’t need them any more.
I use the RENAME statement to rename datefixed to date_entered and I’m ready to go ahead with combining my datasets.
DATA ansfix1 ;
SET flo_answers ;
LENGTH datefixed $19 ;
datefix1 = SUBSTR(date_entered,12,2);
datefixn = datefix1 +5 ;
datefixed = TRIM(SUBSTR(date_entered,1,11)) || ” ” || TRIM(LEFT(datefixn)) || SUBSTR(date_entered,14,6) ;
DROP date_entered datefix1 datefixn ;
RENAME datefixed = date_entered ;
They’re fun and will make you smarter – just like this blog!
Check out the games that provided these data!

Buy one for your family or donate to a child or school.
That date trick was a lot of work. I can’t think of many situations where it’s better to keep the date field as a CHAR instead of a number. I would have used INPUT(date_entered,anydtdtm19.) to convert to a number, then you could simply subtract (5*60*60) (5 hrs, 60min each with 60 sec each). Then use a format for reporting.
data a;
length date_entered $ 19 dt 8;
format dt is8601dt.;
date_entered = ‘2015-08-20 13:23:30’;
dt=input(date_entered,anydtdtm19.);
run;
“Converting a char to a date” is pretty much the #1 viewed topic on SAS support.
That’s a very good point. The con is that I would then have to change the date variable in BOTH datasets as opposed to just changing it in one. The pro would be then I’d have it as an actual date variable so that in the future I could do analyses on it if I should so choose, like average number of answers in a session. Thinking about it, the pros definitely outweigh the cons, even if they are in a hypothetical future, since the future has a way of arriving
Many web-based systems record transaction times in UTC (known as GMT before the Internet). When you want to report using local time, you can add your local offset by adding tzoneoff() (SAS 9.4) or gmtoff() (undoc’d function prior to 9.4). Not sure if that’s what you have going on here, but that might be a way to normalize your time values.